Goal
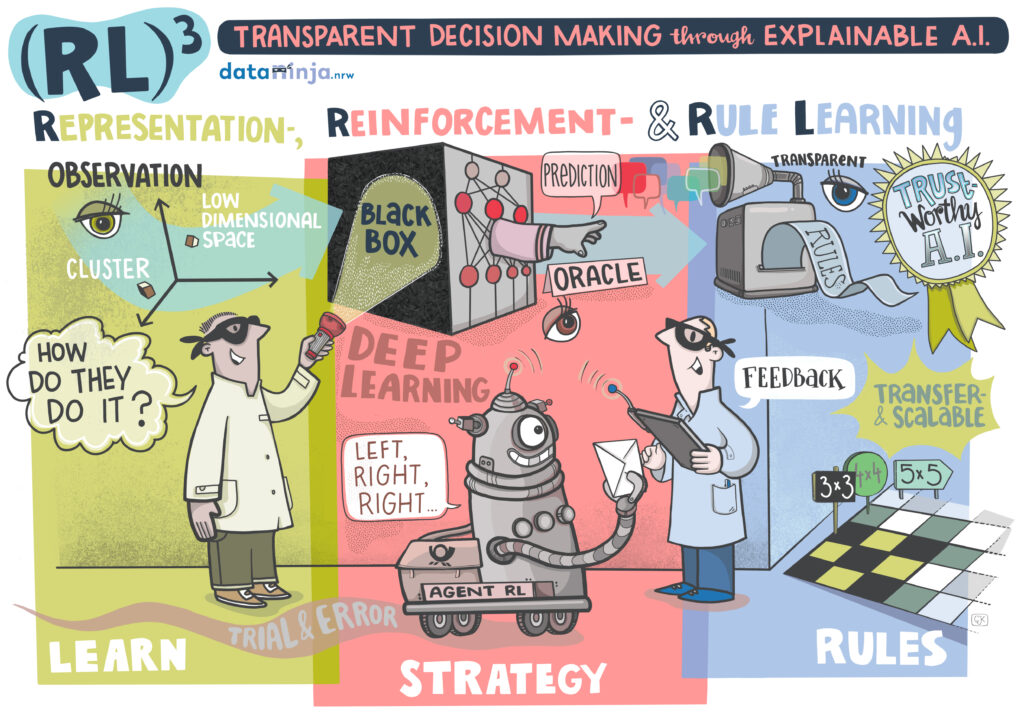
While reinforcement learning methods are steadily gaining in popularity and relevance, complex models often lead to non-transparent behavior and their usefulness is tied to narrowly defined tasks. The (RL)3 project aims to improve both interpretability and transferability in reinforcement learning by using understandable data representations as well as rule-based simplifications of neural networks.
Moritz Lange and Prof. Laurenz Wiskott focus on finding data representations to improve the training of reinforcement learning agents and the interpretability of their decisions. The work of Raphael Engelhardt and Prof. Wolfgang Konen aims at developing automated ways to extract human-understandable rules from trained agents.
Project Overview
Reinforcement learning is an approach to AI in which an agent learns to dynamically interact with its environment to achieve a certain goal. These agents, which are becoming impressively successful across applications from playing games to controlling industrial processes, are commonly based on deep neural networks. However, despite their usefulness, neural networks are notoriously seen as black-box models: their complexity makes them hard to understand and to reason about their decisions. Additionally, the resulting complex and highly specific reinforcement learning algorithms end up being heavily tailored towards specific tasks. (RL)3 will improve the interpretability and transferability of those algorithms to achieve more understandable, more predictable reinforcement learning approaches that are ultimately more secure and easier to apply.
Creating understandable data representations and formulating decision processes as simple rules are among the most efficient approaches to achieve interpretability. Our representation learning research will focus on unsupervised techniques that can learn interpretable data representations independent of specific tasks. Our rule-learning research will simultaneously investigate methods for transforming complex, high-performing reinforcement learning models into simple rules which can be interpreted and modified by domain experts. The developed approaches will be tested on games and in industrial applications.
1–4
Preliminary Results
We developed a first approach of rule learning based on observing a trained reinforcement learning agent interacting with its environment. From the recorded data, containing the environment’s state and the corresponding action of the agent, we induce decision trees. For simple benchmark problems we could show that human-readable decision trees of very limited complexity perform equally well as the black-box deep reinforcement agents they are based on.
Our results have been published as an extended abstract and presented during the poster session of the workshop „Trustworthy AI in the Wild“ at KI 2021 – 44th German Conference on Artificial Intelligence
Project Publications
- Engelhardt, Raphael C., Moritz Lange, Laurenz Wiskott, and Wolfgang Konen (2021). ‘‘Shedding Light into the Black Box of Reinforcement Learning’’. In: Workshop ‘‘Trustworthy AI in the Wild’’ at KI2021 — 44th German Conference on Artificial Intelligence (Berlin, Germany (virtual), Sept. 27–Oct. 1, 2021). url: https://dataninja.nrw/wp-content/ uploads/2021/09/1_Engelhardt_SheddingLight_Abstract.pdf.
- Engelhardt, Raphael C., Moritz Lange, Laurenz Wiskott, and Wolfgang Konen (2023). ‘‘Sample-Based Rule Extraction for Explainable Reinforcement Learning’’. In: Lecture Notes in Computer Science. Vol. 13810: Machine Learning, Optimization, and Data Science (LOD 2022) (Certosa di Pontignano, Italy, Sept. 19–22, 2022). Ed. by Giuseppe Nicosia, Varun Ojha, Emanuele La Malfa, Gabriele La Malfa, Panos Pardalos, Giuseppe Di Fatta, Giovanni Giuffrida, and Renato Umeton. Cham, Switzerland: Springer Nature, pp. 330–345. isbn: 978-3-031-25599-1. doi: 10.1007/978-3-031-25599-1_25.
- Engelhardt, Raphael C., Moritz Lange, Laurenz Wiskott, and Wolfgang Konen (2024). ‘‘Exploring the Reliability of SHAP Values in Reinforcement Learning’’. In: Communications in Computer and Information Science. Vol. 2155: Explainable Artificial Intelligence (xAI 2024) (Valletta, Malta, July 17–19, 2024). Ed. by Luca Longo, Sebastian Lapuschkin, and Christin Seifert. Cham, Switzerland: Springer Nature, pp. 165–184. isbn: 978-3-031-63800-8. doi: 10.1007/978-3-031-63800-8_9.
- Engelhardt, Raphael C., Moritz Lange, Laurenz Wiskott, and Wolfgang” Konen (2023). ‘‘Finding the Relevant Samples for Decision Trees in Reinforcement Learning’’. In: Online Proceedings of the Dataninja Spring School 2023 (Bielefeld, Germany, May 8–10, 2023). url: https://dataninja.nrw/?page_id=1251.
- Engelhardt, Raphael C., Marc Oedingen, Moritz Lange, Laurenz Wiskott, and Wolfgang Konen (2023). ‘‘Iterative Oblique Decision Trees Deliver Explainable RL Models’’. In: Algorithms 16.6: Advancements in Reinforcement Learning Algorithms, p. 282. issn: 1999-4893. doi: 10.3390/a16060282. url: https://www.mdpi.com/1999-4893/16/6/282.
- Engelhardt, Raphael C., Ralitsa Raycheva, Moritz Lange, Laurenz Wiskott, and Wolfgang Konen (2024). ‘‘Ökolopoly: Case Study on Large Action Spaces in Reinforcement Learning’’. In: Lecture Notes in Computer Science. Vol. 14506: Machine Learning, Optimization, and Data Science (LOD 2023) (Grasmere, United Kingdom, Sept. 22–26, 2023). Ed. by Giuseppe Nicosia, Varun Ojha, Emanuele La Malfa, Gabriele La Malfa, Panos M. Pardalos, and Renato Umeton. Cham, Switzerland: Springer Nature, pp. 109–123. isbn: 978-3-031-53966-4. doi: 10.1007/978-3-031-53966-4_9.
- Lange, Moritz, Raphael C Engelhardt, Wolfgang Konen, and Laurenz Wiskott (2024a). ‘‘Interpretable Brain-Inspired Representations Improve RL Performance on Visual Navigation Tasks’’. In: Workshop ‘‘eXplainable AI approaches for Deep Reinforcement Learning’’ at The 38th Annual AAAI Conference on Artificial Intelligence (Vancouver, Canada, Feb. 20–27, 2024). url: https://openreview.net/forum?id=s1oVgaZ3dQ.
- Lange, Moritz, Raphael C. Engelhardt, Wolfgang Konen, and Laurenz Wiskott (2024b). ‘‘Beyond Trial and Error in Reinforcement Learning’’. In:DataNinja sAIOnARA 2024 Conference (Bielefeld, Germany, June 25–27, 2024). Ed. by Ulrike Kuhl, pp. 58–61. doi: 10.11576/dataninja-1172. url: https://biecoll.ub.uni-bielefeld.de/index.php/dataninja/issue/view/82.
- Lange, Moritz, Noah Krystiniak, Raphael C. Engelhardt, Wolfgang Konen, and Laurenz Wiskott (2024). ‘‘Improving Reinforcement Learning Efficiency with Auxiliary Tasks in Non-visual Environments: A Comparison’’. In:Lecture Notes in Computer Science. Vol. 14506: Machine Learning, Optimization, and Data Science (LOD 2023) (Grasmere, United Kingdom, Sept. 22–26, 2023). Ed. by Giuseppe Nicosia, Varun Ojha, Emanuele La Malfa, Gabriele La Malfa, Panos M. Pardalos, and Renato Umeton. Cham, Switzerland: Springer Nature, pp. 177–191. isbn: 978-3-031-53966-4. doi: 10.1007/978-3-031-53966-4_14.
- Melnik, Andrew, Robin Schiewer, Moritz Lange, Andrei Ioan Muresanu, mozhgan saeidi, Animesh Garg, and Helge Ritter (2023). ‘‘Benchmarks for Physical Reasoning AI’’. In: Transactions on Machine Learning Research. Survey Certification. issn: 2835-8856. url: https://openreview.net/forum?id=cHroS8VIyN.
- Oedingen, Marc, Raphael C. Engelhardt, Robin Denz, Maximilian Hammer, and Wolfgang Konen (2024). ‘‘ChatGPT Code Detection: Techniques for Uncovering the Source of Code’’. In: AI 5.3, pp. 1066–1094. issn: 2673-2688. doi: 10.3390/ai5030053. url: https://www.mdpi.com/2673-2688/5/3/53.
Cooperation
References
- 1.N. Escalante A, Wiskott L. Improved graph-based SFA: information preservation complements the slowness principle. Machine Learning. 2019;109:999-1037.
- 2.S. Bagheri, M. Thill, P. Koch, W. Konen. Online Adaptable Learning Rates for the Game Connect-4. IEEE Transactions on Computational Intelligence and AI in Games. 2016;8:33-42. doi:10.1109/TCIAIG.2014.2367105
- 3.Konen W, Bagheri S. Reinforcement Learning for N-Player Games: The Importance of Final Adaptation. In: Vasile M, Filipic B, eds. 9th International Conference on Bioinspired Optimisation Methods and Their Applications (BIOMA) . ; 2020. http://www.gm.fh-koeln.de/ciopwebpub/Konen20b.d/bioma20-TDNTuple.pdf
- 4.Legenstein, Robert AND Wilbert, Niko AND Wiskott, Laurenz. Reinforcement Learning on Slow Features of High-Dimensional Input Streams. PLOS Computational Biology. 2010;6:1-13. doi:10.1371/journal.pcbi.1000894