Goal
Data annotations are necessary to train an artificial intelligence in the setting of supervised learning. The amount of annotation and the processes to control and to improve the quality of the data and annotations are critical. Uncertainty quantification (UQ) methods can make data acquisition and annotation processes much more efficient than manual methods. Manual annotation, e.g. of image content from high-resolution image data, is associated with high costs and other inconveniences. In image classification, an image primarily shows a single object and has a single class label (e.g. dog or cat). In object detection, an image can contain multiple objects, each of which has a bounding box annotation and a class label, and in semantic segmentation a class label is assigned to each image pixel. While image classification still requires a manageable annotation effort, this changes fundamentally for semantic segmentation. The review of such datasets with respect to the annotation quality is also associated with a high effort. In practice, for example, all annotated images of street scenes are often subjected to multiple review processes. Consequently, the processes of data and annotation acquisition can be made much more efficient than what is possible with manual methods.
Project Overview
Data-centric AI focuses on examining and understanding the data. There are several areas in data-centric AI and one of them, our research goal, is to find atypical/anomalous examples in datasets, because data is often a source of unexpected surprises and it helps to understand the data. On one hand, data can be anomalous in terms of untypical constellations in the feature space. On the other hand, boring and monotonous annotation labor leads to atypical examples in terms of incorrect labels.

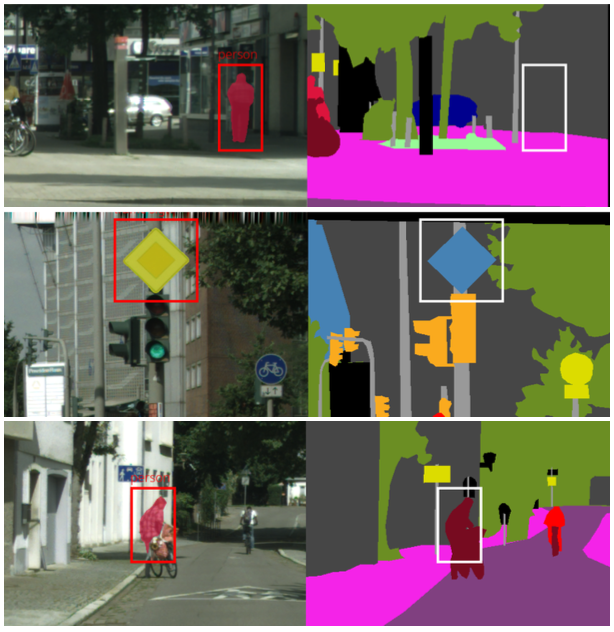
Finding anomalous examples in datasets helps to understand unexpected cases and it is possible to improve the quality of the dataset. It also makes it easier to understand what to expect from a model. While for structured data this is a rather simple and standard task, for unstructured data (e.g. images, videos) and complex computer vision tasks (e.g. object recognition, semantic segmentation) it is a challenge that requires method development.
1–3
Preliminary Results
First, we developed a generative model called LU-Net, which is an invertible neural network based on matrix factorization. LU-Net is a generative model and popular tasks of generative models are sampling and density estimation. LU-Net is capable of assigning meaningful likelihoods. That means, images that are more characteristic of the associated class are assigned higher likelihoods and unusual examples are assigned lower likelihoods. Via the low likelihood cases we detected examples with ambiguous image features.
Moreover, we developed a method termed LidarMetaDetect (LMD), which is a post-processing tool for prediction quality estimation for object detection in 3D Lidar point clouds. We used this method to detect label errors in Lidar based object detection datasets. The idea is to use object detection and uncertainty quantification to detect label errors. If the object detector makes a prediction of high confidence which conflicts the labels, we review that case. It turns out that many of these cases are indeed label errors.
Project Publications
- Penquitt S, Chan R & Gottschalk H. LU-Net: Invertible Neural Networks Based on Matrix Factorization. International Joint Conference on Neural Networks (IJCNN) 2023, Queensland, Australia. https://arxiv.org/abs/2302.10524
- Riedlinger T, Schubert M, Penquitt S, Kezmann J, Colling P, Kahl K, Roese-Koerner L, Arnold M, Zimmermann U & Rottmann M. LMD: Light-weight Prediction Quality Estimation for Object Detection in Lidar Point Clouds. DAGM German Conference on Pattern Recognition (DAGM GCPR) 2023, Heidelberg, Germany. https://arxiv.org/abs/2306.07835
Associated Partners

References
- 1.Li Deng. The MNIST Database of Handwritten Digit Images for Machine Learning Research [Best of the Web]. IEEE Signal Process Mag. Published online November 2012:141-142. doi:10.1109/msp.2012.2211477
- 2.Rottmann M, Reese M. Automated detection of label errors in semantic segmentation datasets via deep learning and uncertainty quantification. IEEE/CVF Winter Conference on Applications of Computer Vision. Published online January 3, 2023. https://openaccess.thecvf.com/content/WACV2023/html/Rottmann_Automated_Detection_of_Label_Errors_in_Semantic_Segmentation_Datasets_via_WACV_2023_paper.html
- 3.Rottmann M, Colling P, Paul Hack T, et al. Prediction Error Meta Classification in Semantic Segmentation: Detection via Aggregated Dispersion Measures of Softmax Probabilities. 2020 International Joint Conference on Neural Networks (IJCNN). Published online July 2020. doi:10.1109/ijcnn48605.2020.9206659